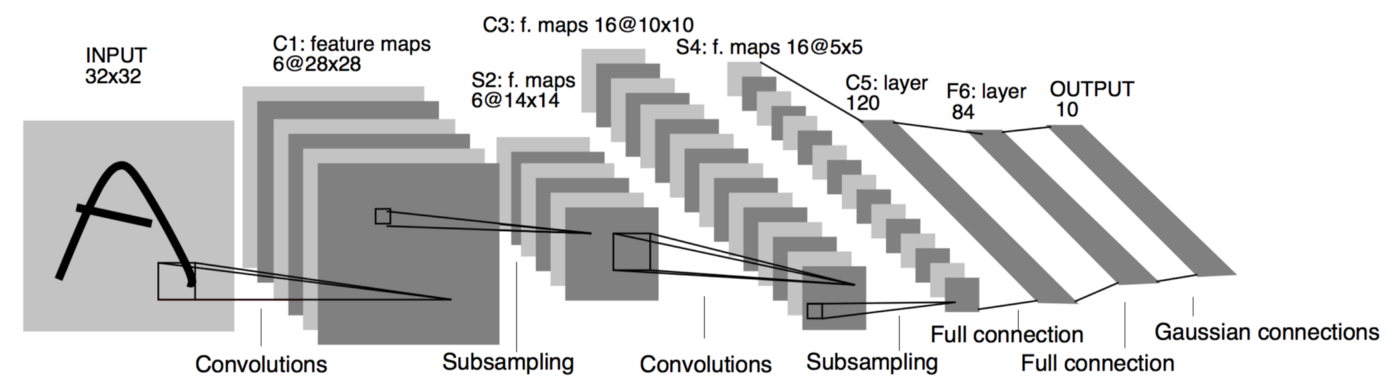
LeNet-5 architecture. Source.
Architecture
LeNet-5 [1998, paper by LeCun et al.]
Main Ideas
convolution, local receptive fields, shared weights, spacial subsampling
Why it is Important
LeNet-5 was used on large scale to automatically classify hand-written digits on bank cheques in the United States. This network is a convolutional neural network (CNN). CNNs are the foundation of modern state-of-the art deep learning-based computer vision. These networks are built upon 3 main ideas: local receptive fields, shared weights and spacial subsampling. Local receptive fields with shared weights are the essence of the convolutional layer and most architectures described below use convolutional layers in one form or another.
Another reason why LeNet is an important architecture is that before it was invented, character recognition had been done mostly by using feature engineering by hand, followed by a machine learning model to learn to classify hand engineered features. LeNet made hand engineering features redundant, because the network learns the best internal representation from raw images automatically.
Brief Description
By modern standards, LeNet-5 is a very simple network. It only has 7 layers, among which there are 3 convolutional layers (C1, C3 and C5), 2 sub-sampling (pooling) layers (S2 and S4), and 1 fully connected layer (F6), that are followed by the output layer. Convolutional layers use 5 by 5 convolutions with stride 1. Sub-sampling layers are 2 by 2 average pooling layers. Tanh sigmoid activations are used throughout the network. There are several interesting architectural choices that were made in LeNet-5 that are not very common in the modern era of deep learning.
First, individual convolutional kernels in the layer C3 do not use all of the features produced by the layer S2, which is very unusual by today’s standard. One reason for that is to made the network less computationally demanding. The other reason was to make convolutional kernels learn different patterns. This makes perfect sense: if different kernels receive different inputs, they will learn different patterns.
Second, the output layer uses 10 Euclidean Radial Basis Function neurons that compute L2 distance between the input vector of dimension 84 and manually predefined weights vectors of the same dimension. The number 84 comes from the fact that essentially the weights represent a 7x12 binary mask, one for each digit. This forces network to transform input image into an internal representation that will make outputs of layer F6 as close as possible to hand-coded weights of the 10 neurons of the output layer.
LeNet-5 was able to achieve error rate below 1% on the MNIST data set, which was very close to the state of the art at the time (produced by a boosted ensemble of three LeNet-4 networks).
Additional Readings
- Understanding Neural Networks Using Excel
- Convolutional Neural Networks (CNNs / ConvNets)
- Paper: “A guide to convolution arithmetic for deep learning”
- Visual explanation of convolution kernels (which are also used also in image processing)
- Convolution animations GIFs
- Probability concepts explained: Maximum likelihood estimation
Return to all architectures
Note: this post was originally published on Medium.